Dagster ETL for Managing YT-DLP
I use an ETL tool, Dagster, to orchestrate YouTube downloads. While this setup might be overkill for most, I decided to experiment with it since I already had a test instance of Dagster running. I’ve grown to appreciate the choice - it easily handles multithreading, supports restarts, and offers a user-friendly GUI for troubleshooting failures.
In this post, I’ll provide a high-level overview of the architecture. The included code snippets are abridged versions, with non-essential lines removed for clarity.
Why Dagster?
Apache Airflow is a powerful open-source platform for ETL workflows, initially developed by Airbnb. If you’ve worked in data engineering over the past decade, there’s a good chance you’ve written an Airflow DAG. Over the years, Airflow has evolved into a thriving ecosystem with numerous plugins and integrations, supported by contributions from more than 3,000 developers. However, the extensive capabilities comes with the overhead of maintaining a sophisticated system.
A few years ago, I inherited an Airflow environment for a small team I managed. We frequently found ourselves fixing and debugging legacy code, despite not requiring many of Airflow’s advanced features. Our primary needs were straightforward: running ETL processes between production and non-production databases and retraining models on a regular schedule. Features like alerts and automatic restarts were convenient, but since our needs were solely for research and development, most of Airflow’s capabilities went unused.
I began to explore lighter weight alternatives to fit our needs and came across Dagster, but before I committed to migrating systems I decided to test it on my home lab. While we never made the move to Dagster, I continued to maintain Dagster for personal usage. I deploy Dagster with docker and allow each run to launch in a new ephemeral container (which can spawn additional containers for parallel operations).
I maintain a couple “DAG” repos which are loaded as a gRPC server on separate ports, allowing me to update a repo without disrupting the Dagster server or other repos. I mostly follow the example docker set-up, however I do separate the user code to a docker-compose file independent of the Dagster services. The gRPC servers are configured in a workspace.yaml file.
Lockdown + New House = Home Lab
Just before the pandemic, I purchased my first house. During lockdown, I became intrigued with setting up a home lab after lurking subreddits like r/homelab and r/HomeServer. It wasn’t long before I purchased a Synology NAS (network attached storage) and set up a Jellyfin server, a right of passage for anyone setting up their first home lab. Bored during lockdown, I started thinking how cool it would be if we could integrate our YouTube channels we regularly watch into Jellyfin. This is when I stumbled upon YT-DLP.
YT-DLP is a killer tool for downloading audio and video files, most popularly used (as the name suggests) for downloading YouTube videos. I began experimenting with YT-DLP to manually download a few YouTube episodes, formatting them, and adding them to my NAS, which was mounted to my home server running Jellyfin. Naturally, the next step was to automate the process.
The simplest choice would be to run some systemd jobs to handle automation, but I was intrigued by the multi-container support offered by Dagster, which I was already running. However, I still use a systemd job to sync the downloads to the NAS and another to clean up the downloads folder. On my TODO list is configuring downloads to go directly to the NAS, but first, I need to set up Jellyfin to ignore partially downloaded files and handle connection interruptions. Here is the script executed by systemd for syncing the downloads while excluding partial files:
#!/bin/bash
rsync -rs --exclude '*.part' --exclude '*.mp4.ytdl' -e "ssh" $YT_DOWNLOADS_PATH $NAS_YT_PATH
And the systemd-managed script used for cleaning files at least 3 days old:
#!/bin/bash
find $YT_DOWNLOADS_PATH -mindepth 1 -mtime +3 -delete
YT-DLP set-up
There is no shortage of discussions and tutorials on using YT-DLP, so I do not plan to go too in-depth, however I’ll provide a high-level overview of my deployment.
I use the Python YT-DLP package instead of the command-line tool since Dagster is also a Python package. In the Python source code (below), YT-DLP settings are configured with a Python dict named YDL_OPTS. Filenames are formatted to be consistent with the recommended Jellyfin TV show schema (outtmpl). The channel’s “season” corresponds to the last 2 digits of the upload the year (e.g., 24 for 2024) while the episode number is represented by the zero-padded month and day (e.g., 0102 for January 2nd). This formatting ensures that episodes are displayed chronologically in Jellyfin.
I also chose to limit video downloads to 1080p .mp4 format, as it strikes a good balance between quality and disk usage. For YouTube channels and playlists, the metadata for the most recent 52 episodes is retrieved (defined by playliststart and playlistend).
YDL_OPTS = {
"playliststart": 1,
"playlistend": 52,
"ignoreerrors": True,
"writethumbnail": True,
"writedescription": True,
"outtmpl": (
f"{YT_HOME}/%(channel)s/Season %(upload_date>%y)s/%(title)s "
"(S%(upload_date>%y)sE%(upload_date>%m%d)s).%(ext)s"
),
"format": "bv*[height<=1080][ext=mp4]+ba[ext=m4a]/b[height<=1080][ext=mp4] / bv*+ba/b"
}
For playlists, I deploy a slightly different naming convention, using a single season for all episodes and inferring the sequential index, replacing the outtmpl so the episodes will appear as <episode title> (S1E1), <episode title> (S1E2), etc.
"outtmpl": (
f"{YT_HOME}/%(channel)s/Season 1/%(title)s "
"(S1E{idx}).%(ext)s"
)
There are additional nuances in the code that I’ve omitted for clarity. For example, it handles discrepancies in playlist ordering—some are numbered chronologically, while others are reversed.
Once the metadata for a given channel is loaded, the video URLs are cross-checked against a PostgreSQL database that tracks the download history. Any URLs not found in the database are added to the download queue. Upon successful download, the corresponding URL is appended to the database to maintain an updated record.
Dagster Integration
Since I started using Dagster, it’s data management philosophy has evolved from a concept of a “solid” to “ops and jobs” to the current core unit of “asset jobs”. When I originally started using Dagster,solids were beginning to be deprecated and the API documentation emphasized ops and jobs. Today, ops are considered an “advanced” feature, implying they are not intended for frequent direct use. However, when I built this pipeline, ops were still central to the framework, and they still fit my use case perfectly.
The DynamicOut op was an ideal solution for dynamically queuing and managing multiple parallel, independent tasks by spawning ephemeral docker containers that shut-down once the task completes. Additionally, it effectively detects and utilizes available host resources to manage orchestration efficiently.
To manage the pipeline I use:
- A YAML file containing all of the YouTube subscriptions.
- 2 Dagster ops: one for queueing channels and one for handling each channels’ YT-DLP task.
- A dagster job to chain the 2 ops
- A dagster schedule
Subscription configuration
My partner and I have very different interests, so we keep our YouTube shows in separate sections on Jellyfin. Hence there are 2 top-level keys in the YAML file for each of us to curate our personal lists under. Below is the beginning of my list:
tim:
3Blue1Brown:
url: https://www.youtube.com/3blue1brown/videos
Queuing
The queuing op creates a generator function that reads from the subscriptions YAML file, yielding a dictionary for each entry while performing data cleaning and validation steps (omitted for brevity). This is where the DynamicOut comes into play. In this setup, the subscriptions YAML file is mounted directly from the host to the Docker container. Resource requirements for the job are evaluated dynamically at runtime, so any updates to the list are reflected in the next run. If the file contains an error—such as a missing key or an invalid value—only the affected entry will fail, allowing the remaining entries to execute without interruption.
from typing import Optional
from dagster import DynamicOut, DynamicOutput, op
@op(out=DynamicOut())
def get_yt_channels(path: Optional[str] = None) -> list[dict]:
yt_chan_list = load_yt_subs_config(path)
for yt_channel in yt_chan_list:
yield DynamicOutput(yt_channel)
Downloading
The actual downloading of metadata and YouTube videos is managed in a separate op. While I’ve excluded a few components tailored to our specific preferences, the most essential elements are provided below. For brevity, I’ve omitted the code for the YT_Channel class, which serves as the central component for managing YouTube metadata, syncing with the PostgreSQL database, and downloading videos. The two key methods in this class are fetch_entries, responsible for downloading metadata, and download_new_videos, which handles video downloads and database synchronization.
@op
def download_new_yt_episodes(yt_channel: dict):
url = yt_channel["url"]
channel = yt_channel["channel"]
parent = yt_channel["parent"]
ytdl = YT_Channel(url, channel, parent)
ytdl.fetch_entries()
ytdl.download_new_videos()
Creating a job out of ops
The ops are chained together to create a job, shown below.
from dagster import job
@job
def refresh_yt_subscriptions():
yt_channels = get_yt_channels()
yt_channels.map(download_new_yt_episodes).collect()
Scheduling and final automation
To run the job on a schedule, the dagster schedule is deployed, which uses CRON-syntax:
from dagster import schedule
@schedule(cron_schedule="5,12,23 * * *", job=refresh_yt_subscriptions)
def refresh_yt_subscriptions_schedule(_context):
return {}
Finally, the definitions are made available to the Dagster service by importing them in the top-level __init__.py file:
from dagster import Definitions
from .jobs import ytdl as ytdl_jobs
from .schedules import ytdl as ytdl_schedules
jobs = [
ytdl_jobs.refresh_yt_subscriptions,
]
schedules = [
ytdl_schedules.refresh_yt_subscriptions_schedule,
]
defs = Definitions(
jobs=jobs,
schedules=schedules,
)
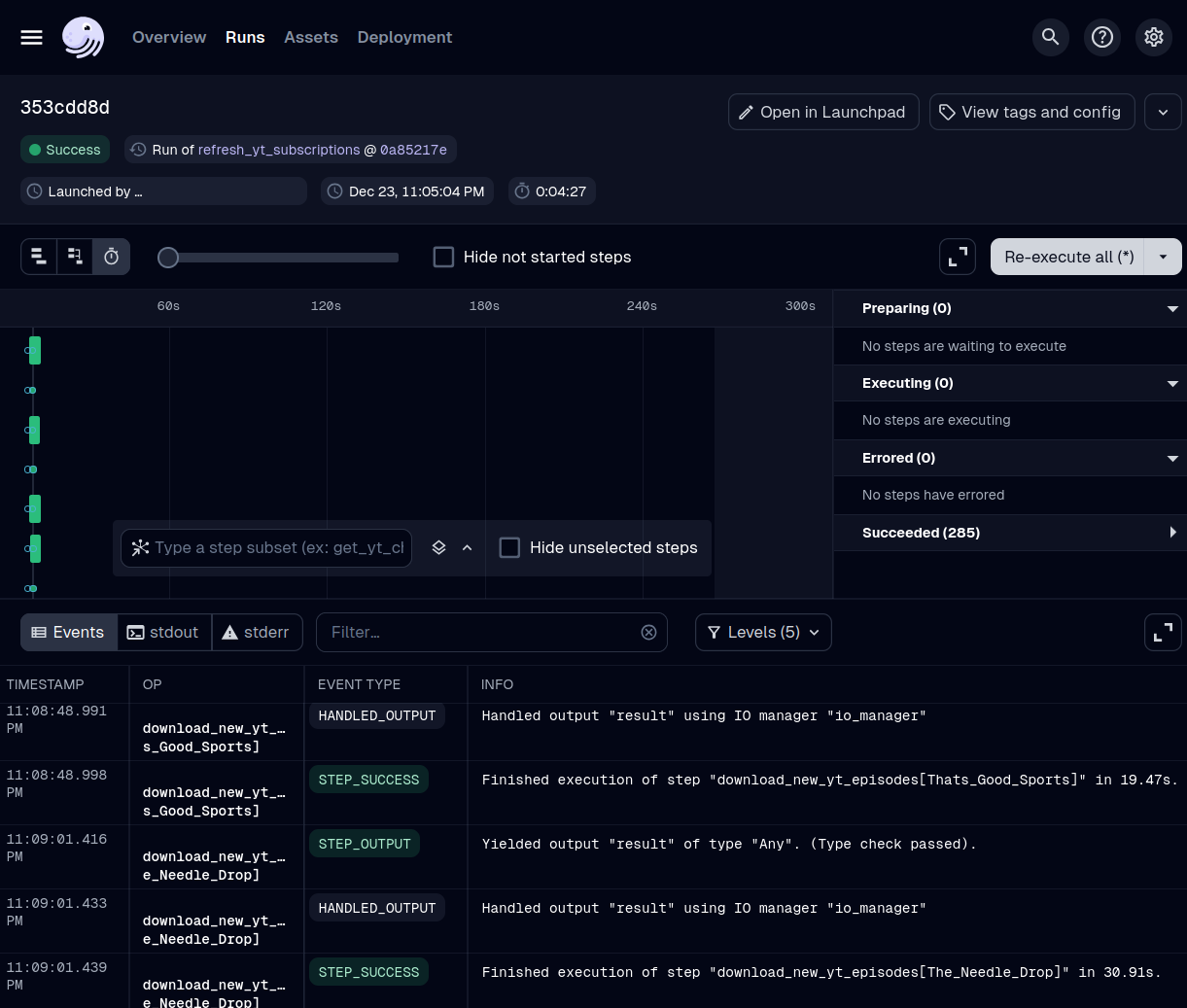
Thank you for reading all the way through! If you’re considering adopting this approach or have any questions, feel free to reach out. Below is a screenshot of a completed run in the Dagster UI. I find this view particularly helpful because it provides a clear starting point for debugging, especially when a variety of issues can lead to failures. From here, I can quickly identify and address any problems with ease.
UPDATE: I have received requests to share the source code; you can find the ugly-but-works code here.